Abstract
Iterative data generation and model re-training can effectively align large language models (LLMs) to human preferences. The process of data sampling is crucial, as it significantly influences the success of policy improvement. Repeated random sampling is a widely used method that independently queries the model multiple times to generate outputs. In this work, we propose a more effective sampling method, named Preference-Guided Reflective Sampling (PRS). Unlike random sampling, PRS employs a tree-based generation framework to enable more efficient sampling. It leverages adaptive self-refinement techniques to better explore the sampling space. By specifying user preferences in natural language, PRS can further optimize response generation according to these preferences. As a result, PRS can align models to diverse user preferences. Our experiments demonstrate that PRS generates higher-quality responses with significantly higher rewards. On AlpacaEval and Arena-Hard, PRS substantially outperforms repeated random sampling in best-of-N sampling. Moreover, PRS shows strong performance when applied in iterative offline RL training.
Background
Best-of-N Sampling
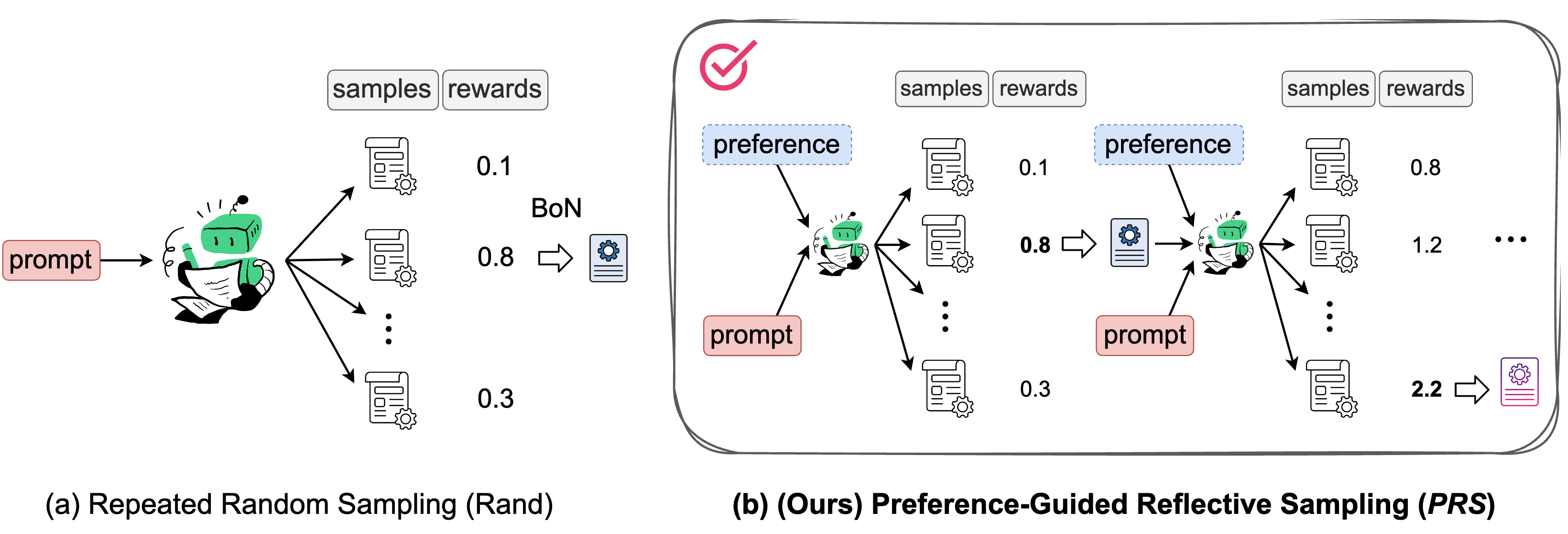
Repeated Random Sampling
In the Best-of-N setting, Random sampling (Rand) is a commonly used and straightforward sampling method. Random sampling generates N independent responses in parallel and uses temperature sampling to control diversity in the generated outputs.
Although random sampling is simple and effective, it has two main drawbacks:
- Low sampling efficiency: Each response is generated independently, meaning new responses cannot learn from previous samples. This affects the quality of responses and limits improvements in sampling efficiency.
- Lack of preference consideration: The goal of language model alignment is to generate responses that match user preferences, yet random sampling does not take user preferences into account during generation. As a result, the responses generated may fail to meet the diverse needs of different users.
Method
.png)
We propose a new sampling method named Preference-Guided Reflective Sampling (PRS). PRS adopts a tree-based generation framework that learns to adapt and adjust its outputs by reflecting on its already generated data. It can incorporate a specific user preference to optimize responses that align with it. Adjusting preferences will generate tailored responses.
Specifically, for a given prompt x and user preference z, PRS enables the model p to generate N responses. PRS employs a tree structure for sampling, which can have multiple layers, each with a corresponding width. For simplicity, PRS defaults to a two-layer structure, with each layer having a width of N/2. Additionally, PRS uses a pre-trained reward model R(x, z, y) to score the generated responses.
- First Layer: Using random sampling, generate
N/2responses, denoted as𝒀₀, based ony₀ ∼ p(⋅ | x, z). - Use the reward model to score each response in
𝒀₀, selecting the response with the highest rewardy₀*. - The model then performs self-reflection based on
y₀*, evaluating ify₀*aligns with the given preferencezand generating corresponding feedbackf. - Second Layer: Based on
y₁ ∼ p(⋅ | x, z, y₀*, f), use random sampling again to generateN/2improved responses, denoted as𝒀₁. - Score each response in
𝒀₁using the reward model. - Finally, combine
𝒀₀and𝒀₁, returning the response with the highest reward among them.
Results
Comparison of Data Sampling Methods:
- Rand: This is the random sampling method.
- PRand: This builds on random sampling by incorporating user preference
zinto the input prompt. - Greedy: The model iteratively modifies the response with the highest current reward.
- PRS: The newly proposed method.
Results of Best-of-N sampling on AlpacaEval and Arena-Hard
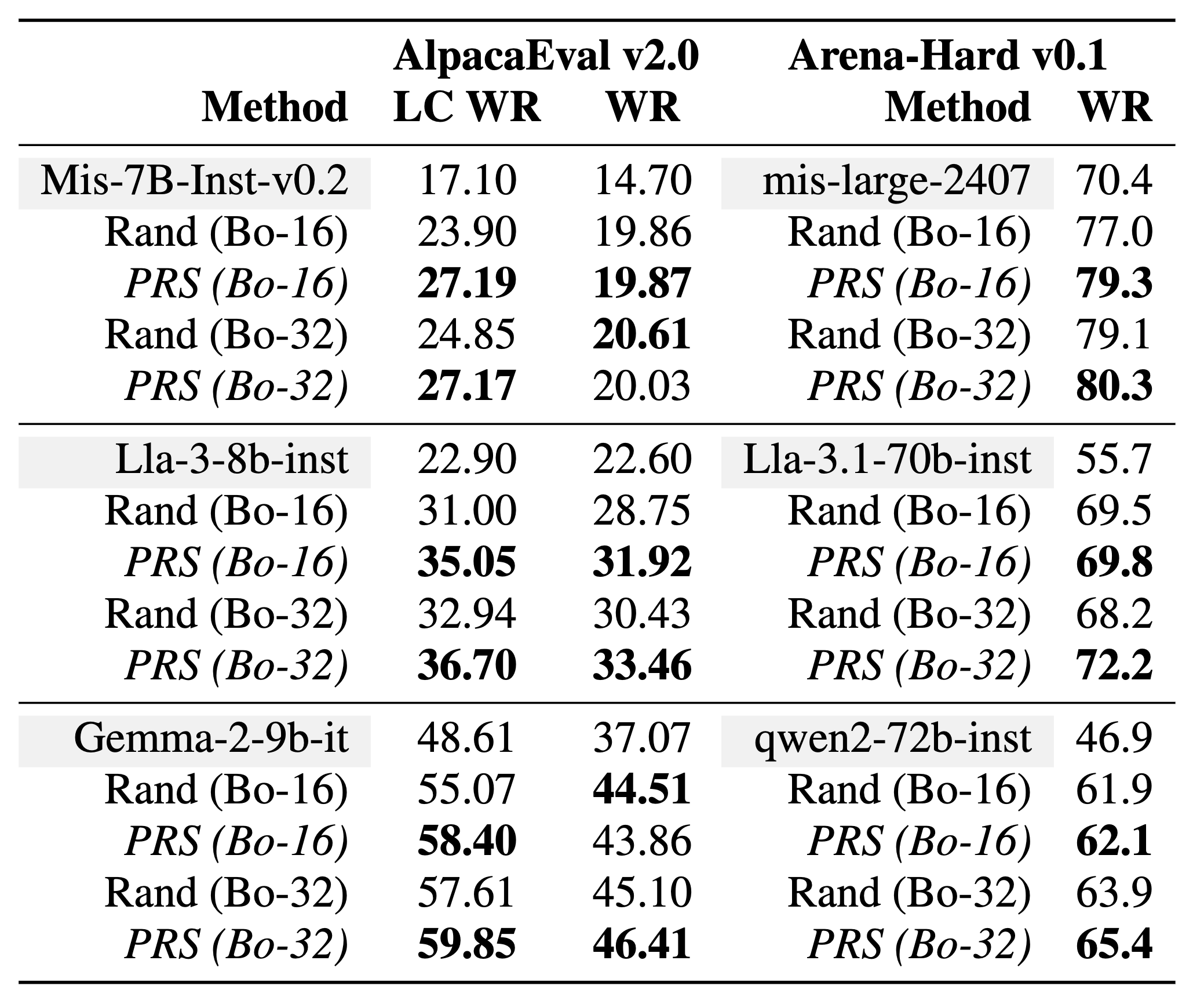
We conducted best-of-N sampling experiments on AlpacaEval and Arena-Hard, where, for the same prompt, we used both random sampling and PRS to generate N responses, retaining the response with the highest reward score.
We tested different language models for sampling: Mistral-7b-instruct-v0.2, Mistral-large-2407, Llama-3-8b-instruct, Llama-3.1-70b-instruct, Gemma-2-9b-it, and Qwen2-72b-instruct. We use ArmoRM-Llama3-8B-v0.1 as the reward model.
We first present the baseline results of different models on AlpacaEval v2.0 and Arena-Hard v0.1. We found that sampling multiple responses and selecting the best one significantly improves model performance. Furthermore, compared to random sampling, PRS consistently shows performance gains in both best-of-16 and best-of-32 settings. This experimental result demonstrates that PRS outperforms random sampling in best-of-N sampling.
Comparison of Sampling Results
.png)
We further compared the reward values of responses generated by different methods at varying sample sizes.
Under different sample sizes, we examined the reward values of responses generated by each sampling method. For PRS, we considered the impact of different tree structure widths and whether feedback was generated. w/o f denotes no feedback generation. Here, we used AlpacaEval prompts to generate responses and UltraRM-13b as the reward function.
PRS (N/2, N/2) and PRS (N/2, N/2) w/o f achieved superior results. We found that PRS demonstrated higher sampling efficiency compared to other methods: at the same sample size, PRS achieved higher reward values; and to reach the same reward value, PRS required less computation. Therefore, PRS is a more compute-optimal method.
Preference Adaptation
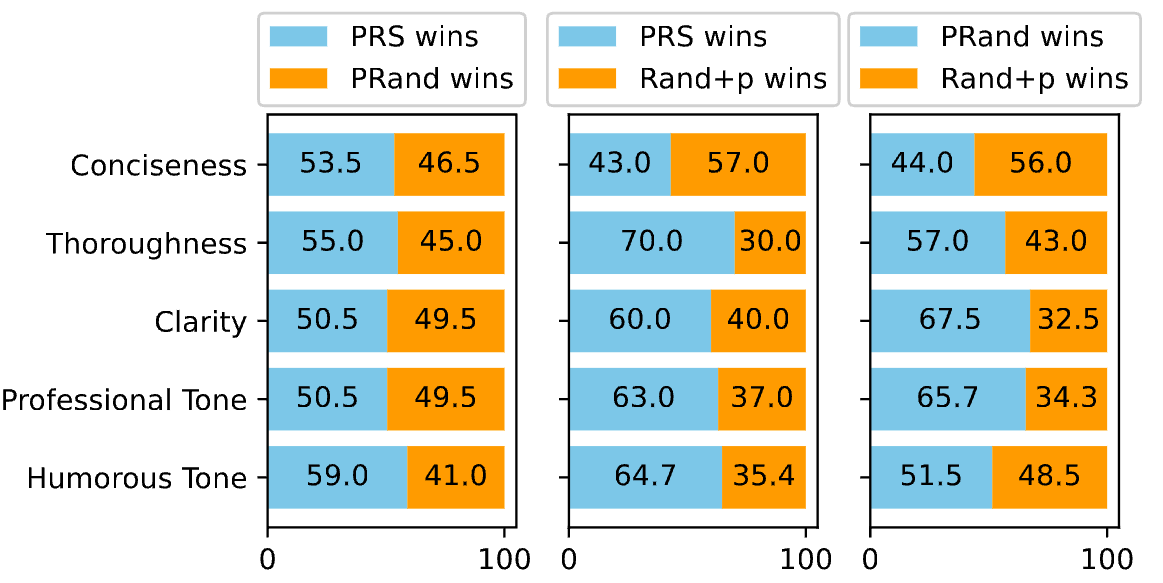
We further compared the effectiveness of PRS in adapting to user preferences (Adaptation) and evaluated the following methods:
We first used these three methods to align a large language model. The specific process is as follows: we used each method to generate data, and then used the generated data to align the language model. This process was repeated three times. During data generation, we accounted for user preferences by pre-labeling each prompt in the training data with different user preferences. For details on the labeling process, please refer to the paper. For data generated by PRand and PRS, we trained the model using a function of the form p(y|x,z), while Rand used the training method p(y|x).
After obtaining the aligned models, we tested five different user preferences. For each test prompt, we appended a user preference description and then input it into the model to generate a corresponding response, i.e., y ∼ p(⋅ | x, z). We used GPT-4 for automatic evaluation to determine which response better matched the user preference. Results indicated that PRS had better adaptability than Rand and PRand, confirming that PRS enables more precise personalized alignment. Additionally, we found that PRand is a strong baseline method—simply appending a preference directive after the prompt can yield effective personalized outputs.
BibTeX
@inproceedings{hai_prs_emnlp,
author = {Ye, Hai and Ng, Hwee You},
booktitle = {Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP)},
title = {Preference-Guided Reflective Sampling for Aligning Language Models},
url = {https://arxiv.org/pdf/2408.12163},
year = {2024}
}